class: center, middle # High Availability __CS291A__ Dr. Bryce Boe October 18, 2018 --- # Today's Agenda * TODO * Scaling Review * High Availability --- # TODO ## Should be done * Chapters 1, 2, 9-11 in [HPBN](https://hpbn.co/primer-on-latency-and-bandwidth/) / Chapters 1-10 in the [Ruby on Rails Tutorial](https://www.railstutorial.org/book/beginning) * [Dynamic Load Balancing on Web-server Systems](http://www.ics.uci.edu/~cs230/reading/DLB.pdf) by Cardellini, Colajanni, and Yu. * Build out a web application with a handful of features. * TravisCI integration with your repository. ## Before next week's lab * Chapters 13, 14 in the [Ruby on Rails Tutorial](https://www.railstutorial.org/book/user_microposts) (read/skim chapters 11 and 12 as you see fit) __Focus__: On delivering new usable features to your customers (me) for the next two weeks. --- # Scaling Review ## Vertical Scaling Buying "bigger" hardware and scaling _up_ * __PRO__: Easy * __CON__: Limited * __CON__: Non-linear increase in cost when scaling ## Horizontal Scaling Buying move servers and scaling _out_ * __PRO__: Easy to add more servers (limited by data center space) * __PRO__: Linear (maybe even sublinear) increase in cost when scaling * __CON__: More moving parts makes things more complicated --- # High Availability Motivation Modern web applications power some very important parts of our lives. * Banking * Medical * Telephony Having anytime access to these services (high availability) is increasingly important. --- # Expressing Availability Companies offering services will often advertise some number of nines availability: * Three nines: 99.9% uptime, 525.6 minutes of downtime a year (43.8/month) * Four nines: 99.99% uptime, 52.6 minutes of downtime a year (4.38/month) * Desired by many business applications * Five nines: 99.999% uptime, 5.3 minutes of downtime a year (26.5s/month) * Desired by communication companies Downtime usually only includes unplanned outages. Scheduled outages, no matter how frequent, are usually not incorporated in marketing material. --- class: center, middle # What are possible causes of failures?  --- # What are possible causes of failures? ## What if... * a server process hangs? * a server process dies? * an application server fails? * a load balancer fails? * a switch fails? * a router fails? * a connection to the Internet fails? * the Internet fails? * a database fails? * an entire data center fails? --- # Handling Application Server Failure .left-column40.center[  ] .right-column60[ We've already discussed the components of this sort of failure. * Process-level isolation reduces hanging, or dead processes by having other processes to pick up the slack. * A process in an infinite loop may add unnecessary load to the server, so it's important to have monitoring to detect such issues. * Having a load-balanced configuration permits failing servers (high load or dead) by having a pool of other servers to direct traffic to. ] --- class: center, middle # How do we Handle Load Balancer Failure?  --- # Redundant Load Balancers .left-column40[ Buy two load balancers. One is the primary, and the other is the failover. Load balancers communicate via a heartbeat to determine the health of each other. ] .right-column60.center[  ] -- .clear[ > During a failover, what happens to established flows? ] -- > During a failover, what happens to the IP address? --- # Load Balancer Failover When the failover load balancer determines it needs to become the primary (detected via lack of heartbeat), it issues a gratuitous ARP for the load balancer's IP. The gratuitous ARP (layer 2) will inform the switch that traffic should be delivered to the port that leads to the new primary (formerly the failover). All new packets will be transparently delivered to the new primary load balancer. Established flows can be supported depending on how much information sharing occurs between the load balancers. --- class: center, middle # How do we Handle Switch Failure?  --- # Redundant Switches Buy two switches! Again with a both a primary and failover and using a heartbeat between them. During failover similar issues occur but layer 2 should be stateless so no/less synchronization needed. .center[] --- class: center, middle # How do we Handle Router Failure?  --- # Redundant Routers Buy two! Similar heartbeat and failover system, with slightly different problems. .center[] --- class: center, middle # How do we Handle Access to the Internet Failure?  --- # How do we Handle Access to the Internet Failure? Buy two! Use separate internet service providers (ISPs). .center[] --- # Routing with Two ISPs > How do we handle routing when we have two ISPs? -- ## Outgoing Traffic (easy) We control how we send outbound traffic so we have some options: * Pick the cheapest or most reliable link * Pick the _closer_ link -- ## Incoming Traffic (hard) We cannot inform clients by which path to reach our IP. However, we can give hints by using BGP to persuade networks to prefer one path over another. (Path prepending, Community values) --- # High Availability .center[] We will discuss database failover in another lecture. --- # Redundancy Everywhere! So we have redundant systems in place. > Can anything go wrong? --- class: center, middle # Disaster Strikes!  --- class: center, middle # Hurricane Sandy via Ars Technica  --- class: center, middle # 2017 Hurricanes  > Yet another data center, west of Houston, was so well prepared for the storm — with backup generators, bunks and showers — that employees’ displaced family members took up residence and United States marshals used it as a headquarters until the weather passed. --- # Availability Axiom (Pete Tenereillo) Source: [http://www.tenereillo.com/GSLBPageOfShame.htm](http://www.tenereillo.com/GSLBPageOfShame.htm) > The only way to achieve high-availability for browser based clients is to > include the use of multiple A records. An "A record" is an IPv4 address associated with a DNS host (AAAA for IPv6 addresses). -- ## Problem The order of DNS responses with multiple A records is often not preserved by a client's DNS server. ## Result * For performance we want to send the browser to one data center. * For availability we want to send the browser multiple A records. We end up having to make a choice between performance and availability. --- class: center, middle # Multi-site High Availability 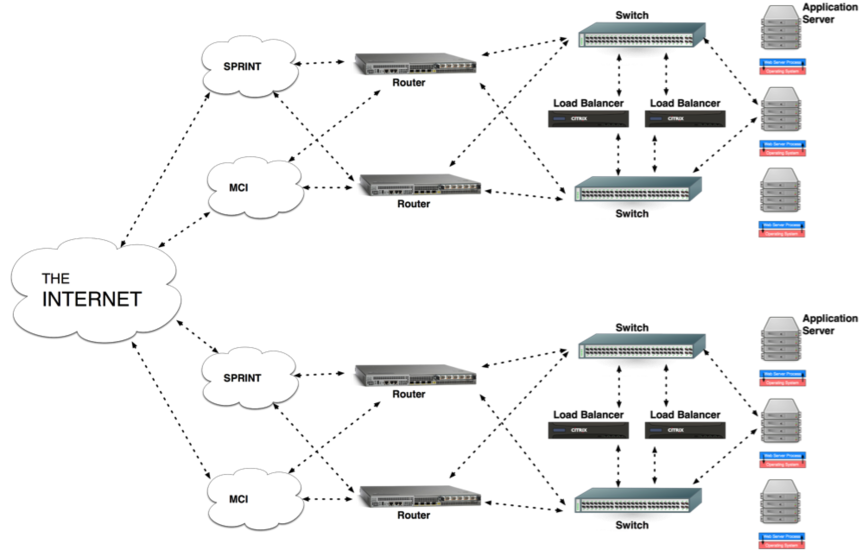 What about the database?