class: center, middle # HTTP and Application Servers __CS291A__ Dr. Bryce Boe October 3, 2019 --- # Today's Agenda * TO-DO * HTTP Servers vs. Application Servers * Server Architectures * C10K Problem * Application Servers --- # TO-DO ## Before 11AM Tuesday: * Complete [Project 1](/project1) ## Before Tuesday's Class: * Read [Dynamic Load Balancing on Web-server Systems](http://www.ics.uci.edu/~cs230/reading/DLB.pdf) by Cardellini, Colajanni, and Yu. --- class: center inverse middle # HTTP Servers vs. Application Servers --- # End to End HTTP By now, we all should have a reasonable understanding of the HTTP protocol. -- Recall that many browsers and clients exist that are able to: * Open a TCP socket * Send an HTTP request * Have the request processed * Receive the data in a response * Reuse the socket for multiple requests -- The software systems that handle the requests are generally divided into two parts: * HTTP Servers * Application Servers --- # Separation of Responsibilities > Why not use a single process to handle both the http request and the > application logic? -- The concerns and design goals of HTTP servers are different from those of application servers. --- # Server Design Goals ## HTTP Server * Provide a high performance HTTP implementation (handles concurrency) * Be extremely stable, and relatively static * Be very configurable and language/framework agnostic -- ## Application Server * Support a specific language (e.g., Ruby), many of which are not optimized for performance * Run _business logic_ which is extremely dynamic --- # HTTP Servers 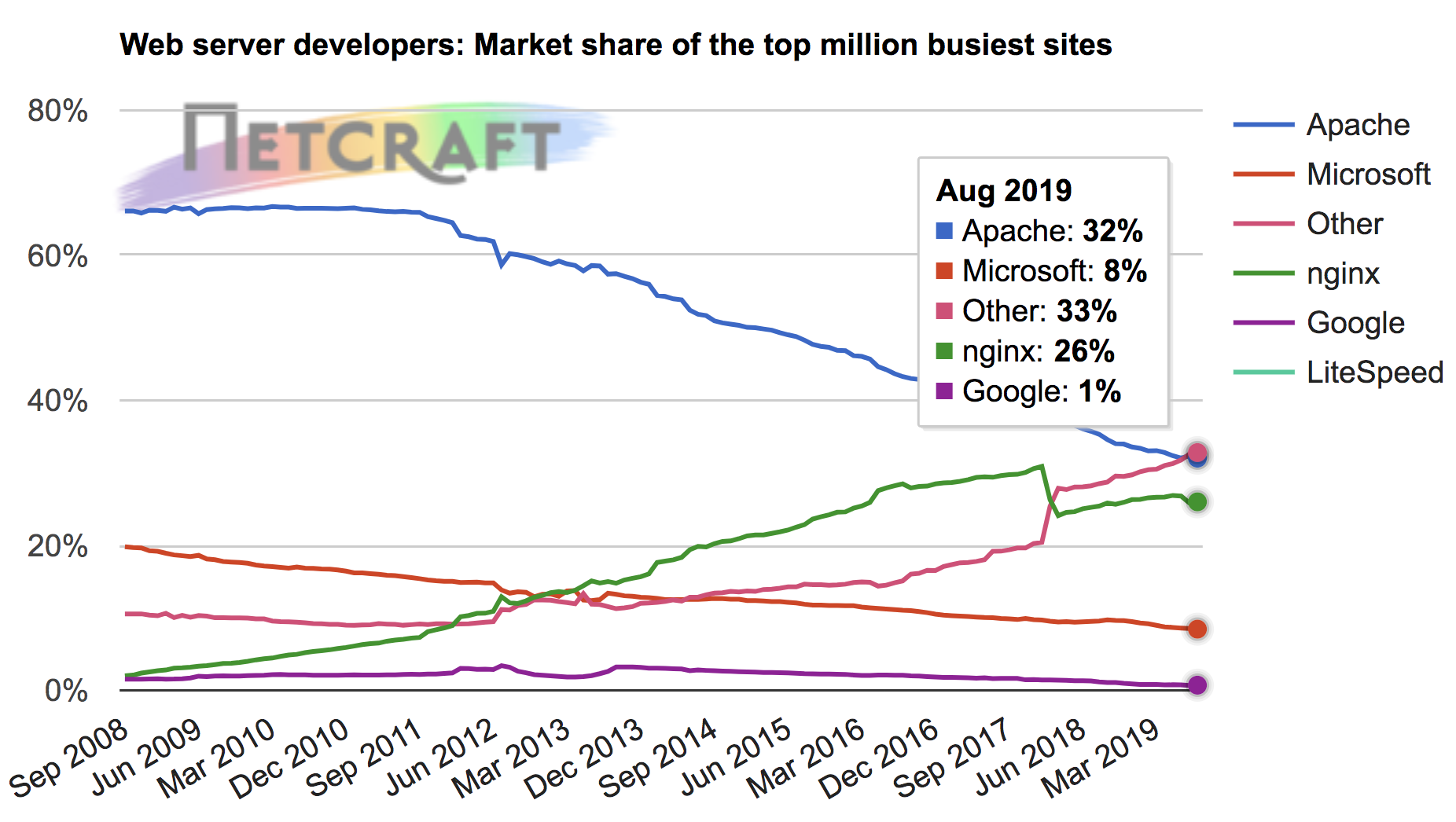 Latest: https://news.netcraft.com/archives/2019/08/15/august-2019-web-server-survey.html --- # HTTP Server Responsibilities * Parse HTTP requests and craft HTTP responses _very_ fast * Dispatch to the appropriate handler and return response * Be stable and secure (lots of string parsing) * Provide clean abstraction for application servers > How do HTTP servers provide concurrency? --- class: center inverse middle # Server Architectures --- # TCP Server Concurrency Approaches * Sequential (no concurrency) * Process per request * Process pool * Thread per request * Process/thread worker pool * Event-driven For select examples see: [https://gist.github.com/bboe/6a7b03fcd110c4c6bbe5ec412f523428](https://gist.github.com/bboe/6a7b03fcd110c4c6bbe5ec412f523428) --- # Sequential Servers ```python bind() to port 80 and listen() loop forever accept() a socket connection while we can read from the socket read() a request process that request write() its response close() the socket connection ``` -- > What happens if another request comes in while we're within the loop? --- # Sequential Server Issues If a sequential HTTP server does not process the request quickly, other clients end up waiting or dropping their connections (**head of line blocking**). We are building complex web applications not simple web sites. As a result: -- * The requests are usually more complicated than serving a file from disk. -- * It is common to have a web request doing a significant amount of computation and business logic. -- * It is common to have a web request result in connections to multiple external services, e.g., databases, and caching stores. -- * These requests can be anything: lightweight or heavyweight, IO intensive or CPU intensive. We can solve these problems if the thread of control that processes the request is separate from the thread that `listen()`s and `accept()`s new connections. --- # Process per Request Servers Handle each request as a subprocess: .left-column40[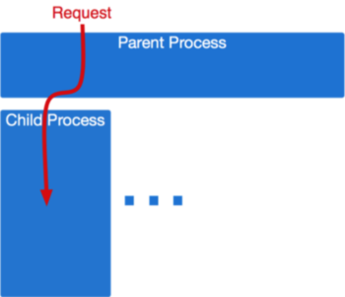] .right-column60[ ```python bind() to port 80 and listen() loop forever accept() a socket connection * if fork() == 0 # child process while we can read from the socket read() a request process that request write() its response close() the socket connection * exit() ``` ] --- # Process per Request Servers ## Strengths * Simple * Provides significant isolation between requests ## Weaknesses * How much memory is required? * What happens as more parallel requests come in? * How efficient is it to start a process on each request? * How much setup and teardown work is necessary? --- # Process Pool Servers .left-column[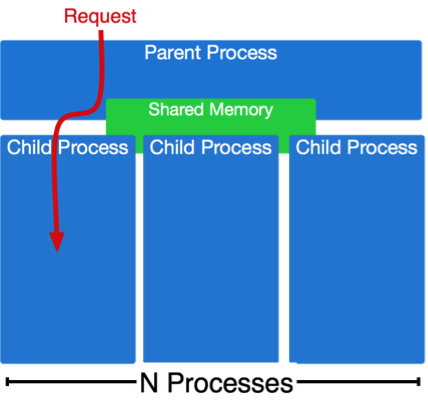] .right-column[ Instead of spawning a process for each request, create a pool of N processes at start-up and have them handle incoming requests when available. The children processes `accept()` the incoming connections and use shared memory to coordinate. The parent process watches the load on its children and can adjust the pool size as needed. ] --- # Process Pool Servers ## Strengths * Provides isolation between concurrent requests * Children can die after _M_ requests to minimize memory leakage issues * Process setup and teardown costs are minimized * More predictable behavior under high load ## Weaknesses * More complex than process per request * Many processes can still mean a large amount of memory consumption This HTTP server architecture is provided by the Apache 2.x MPM "Prefork" module. --- # Thread per Request Servers Why use multiple processes at all? Instead we can use a single process and spawn new threads for each request. .left-column40[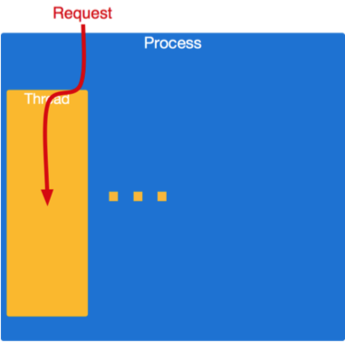] .right-column60[ ```python bind() to port 80 and listen() loop forever accept() a socket connection * pthread_create() while we can read from the socket read() a request process that request write() its response close() the socket connection pthread_exit() ``` ] --- # Thread per Request Servers ## Strengths * Relatively simple * Reduced memory footprint compared to multi-processed ## Weaknesses * Worker (request handling code) must be thread-safe * Setup and teardown needs to occur for each thread (or shared data needs to be thread-safe) * What about memory leaks? --- # Process/Thread Worker Pool Servers .left-column[] .right-column[ Combination of the two techniques. Master process spawns processes, each with many threads. Master maintains process pool. Processes coordinate through shared memory to `accept()` requests. Fixed threads per request, scaling is done at the process level. ] --- # Process/Thread Worker Pool Servers ## Strengths * Faults isolated between processes, but not threads * Threads reduce memory footprint * Tunable level of isolation * Controlling the number of processes and threads allows for predictable behavior under load ## Weaknesses * Requires thread-safe code * Uses more memory than an all-thread based approach This HTTP server architecture is provided by the Apache 2.x MPM "Worker" module. --- class: center inverse middle # Digression: C10K Problem --- # C10K Problem > Given a 1 GHz machine with 2GB of RAM, and a gigabit Ethernet card, can we > support 10,000 simultaneous connections? -- ## 20,000 clients means each client gets: * 50 KHz of CPU * 100 KB of RAM * 50 Kb/second of network -- > It shouldn't take any more horsepower than that to take four kilobytes from > the disk and send them to the network once a second for each of twenty thousand > clients. Originally posed in 1999 by Dan Kegel. Source: [http://www.kegel.com/c10k.html](http://www.kegel.com/c10k.html) --- class: center middle # What makes managing concurrent connections difficult? --- # For each client the server is... * Reading from the network socket * Parsing its request * Opening a file on disk * Reading the file into memory * Writing the memory to network --- # For each client the server is... __blocking on I/O__ * Reading from the network socket (__blocking__) * Parsing its request * Opening a file on disk (__blocking__) * Reading the file into memory (__blocking__) * Writing the memory to network (__blocking__) --- # Waiting on I/O Every time a process/thread is waiting on I/O it is not runnable, and it is not cost-free: * Each process/thread is considered every time the scheduler makes a decision * Memory is occupied by the process, and its last load may have evicted other processes' memory from the cache Massive concurrency slows down all processes/threads. --- # How can we not wait on I/O? Blocking system calls cause this problem. > Can we accomplish our desired tasks without blocking? -- ## Yes! Using Asynchronous I/O Use a non-blocking version of I/O system calls in combination with: * `select()`: Provided a list of file descriptors, block only until at least one is ready for I/O (only usable up to file descriptor number 1023 on Linux). * `epoll_*()`: (Linux) Register to listen for events on file descriptors. Again block only until at least one of the registered descriptors is ready for I/O --- # Select example Assume we have a list of sockets called fd_list. ```python loop forever: select(fd_list, ...) // block until something has I/O to handle for fd in fd_list if fd is ready for IO handle_io(fd) else do nothing ``` -- ## handle_io * can include socket acceptance * shouldn't make any blocking calls (use non-blocking variants) * should avoid excessive computation * Use a separate thread, process, or worker pool for such purposes --- # Event Driven Systems Systems that operate in such a manner are called event driven systems. Often such systems can accomplish everything using only a single process and thread, of course more may be needed for CPU-bound segments. Well used examples: * NGINX * lighttpd * netty (java) * node.js (JavaScript) * eventmachine (ruby) * twisted (python) --- # Event Driven Servers ## Strengths * High performance under high load * Predictable performance under high load * No need to be thread-proof (unless specifically adding thread-concurrency) -- ## Weaknesses * Poor isolation * What happens if a bug causes an infinite loop? * Extensions are hard to implement since they cannot use blocking syscalls * Very complex --- # Event Machine (Ruby) Example Event driven code is dominated by callbacks: ```ruby EM.run { test = EM::HttpRequest.new('http://google.com/').get test.errback { puts "Google is down! terminate?" } test.callback { search = EM::HttpRequest.new('http://google.com/search?q=em').get search.callback { # callback nesting, ad infinitum } search.errback { # error-handling code } } } ``` --- # Callback Hell .center[] With all these callbacks, event-drived programming _can_ very easily become complicated. --- # Server Architectures Review .left-column[ * Sequential (single process and thread) * Easy * No concurrency * Process per request * Greatest isolation * Largest memory footprint * Thread per request * Less isolation * Smaller memory footprint ] .right-column[ * Process/thread worker pool * Tunable compromise between processes and threads * Event-driven * Great performance under high load * Difficult to extend * Reduced isolation ] --- class: center inverse middle # Application Servers --- # Application Servers We are building web applications, so we will require complex server-side logic. We _can_ extend our HTTP servers to provide this logic through modules, but there are benefits to separating application servers into one ore more distinct processes. Because: -- * Application logic will be dynamic * Application logic regularly uses high level (slow) languages * Security concerns are easier (HTTP server can shield app server from malformed requests) * Setup costs can be amortized if the app server is running continuously --- class: center middle # How does an HTTP Server communicate with the application server(s)? --- # Inter-server Communication ## [CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface) Spawn a process, pass HTTP headers as ENV variables and utilize STDOUT as the response. -- ## [FastCGI](https://en.wikipedia.org/wiki/FastCGI), [SCGI](https://en.wikipedia.org/wiki/Simple_Common_Gateway_Interface) Modifications to CGI to allow for persistent application server processes (amortizes setup time). -- ## HTTP Communicate via the HTTP protocol to a long-running process. (Essentially a reverse-proxy configuration). > Does it make sense to have the application server speak HTTP? --- # Application Server Architectures > What architecture should we use for our application server? -- We have the same trade-offs to consider as with HTTP servers (e.g. threads, processes, and/or workers), so we needn't revisit them again. --- # Up Next Let's take a quantitative look at various approaches used in actual Ruby application servers. We will not consider evented ruby application servers (e.g., EventMachine) because Rails will not run on such application servers. --- # Our Test Setup  The [Demo App](https://github.com/scalableinternetservices/demo) is a link sharing website with: * Multiple communities * Each community can have many submissions * Each submission can have a tree of comments --- # Simulated Users Using [Tsung](http://tsung.erlang-projects.org/) (erlang-based test framework) we will simulate multiple users visiting the Demo App web service. Each user will: ``` Visit the homepage (/) Wait randomly between 0 and 2 seconds Request community creation form Wait randomly between 0 and 2 seconds Submit new community form Request new link submission form Wait randomly between 0 and 2 seconds Submit new link submission form Wait randomly between 0 and 2 seconds Delete the link Wait randomly between 0 and 2 seconds Delete the community ``` --- # Test Process There are six phases of testing each lasting 60 seconds: 1. (0-59s) Every second a new simulated user arrives 2. (60-119s) Every second 1.5 new simulated users arrive 3. (120-179s) Every second 2 new simulated users arrive 4. (180-239s) Every second 2.5 new simulated users arrive 5. (240-299s) Every second 3 new simulated users arrive 6. (300-359s) Every second 3.5 new simulated users arrive __Note__: Each user corresponds to seven requests and a user may wait up to ten seconds with the delays. --- # Test Environment All tests were conducted on a single Amazon EC2 m3-medium instance. * 1 vCPU * 3.75 GB RAM The tests used the `Puma` application server (unless otherwise specified). The `database_optimizations` branch of the demo app was used to run the tests: [https://github.com/scalableinternetservices/demo/tree/database_optimizations](https://github.com/scalableinternetservices/demo/tree/database_optimizations) --- # Single Thread/Process (Users) .center[] --- # Single Thread/Process (Page Load) .left-column20[ Decrease in performance around 60s (1.5 new users per second) Mean duration's spike is around 200 seconds. ] .right-column80[ .center[] ] --- # Four Processes (Users)  --- # Four Processes (Page Load) .left-column20[ Decrease in performance around 240s (3 new users per second) Mean duration's spike is just below 18 seconds. ] .right-column80[  ] --- # Sixteen Processes (Users)  --- # Sixteen Processes (Page Load) .left-column20[ Decrease in performance around 240s (3 new users per second) Mean duration's spike is just below 14 seconds. Little improvement over 4 processes especially considering up to 4x memory usage. ] .right-column80[  ] --- # Threads instead of processes? > What do you think will happen? --- # Four Threads (Users)  --- # Four Threads (Page Load) .left-column20[ Still decrease in performance around 240s, but more stable until then. Mean duration's spike is about 14 seconds. ] .right-column80[  ] --- # 32 Threads (Users)  --- # 32 Threads (Page Load) .left-column20[ Decrease in performance beginning around 300s (3.5 new users per second) Mean duration's spike is under 2 seconds. ] .right-column80[  ] --- # Digression: Ruby interpreters There are different versions of the Ruby interpreter. Different workloads may benefit from using different interpreters. ## MRI (Matz's Ruby Interpreter) * The reference version * Written in C * Has a global interpreter lock (GIL) that prevents true thread-concurrency ## JRuby * Written in Java * Does not have GIL --- # Application Server Options You will be able to compare the performance of two application servers when working on the primary project: ## via elastic beanstalk configuration * Puma (worker pool) * Phusion Passenger (worker pool) --- # Puma Originally designed for Rubinius (GIL-less ruby interpreter). Claims to require less memory than others (for the server itself) Specifically made to work with thread-based parallelism, but also supports multiple processes each with a tunable number of threads. --- # Phusion Passenger Passenger is a ruby application server that can be added as a module to either Apache or NGINX. Passenger works as a worker pool adjusting the number of processes that handle requests. Originally did not support threads within the processes. --- # Puma and Passenger Both Puma and Phusion Passenger: * are relatively easy to configure * enable processes to be forked after ruby/rails is loaded > Why might you want to wait to load the application prior to forking? --- # Thread Safety Note If you can use thread-parallelism, do it! But, making your code thread safe isn't always obvious. Things to consider: * Your code * Your code's many dependencies