class: center, middle # Application Servers ## CS291A: Scalable Internet Services ### Dr. Bryce Boe --- # Separation of Responsibilities > Why not use a single process to handle both the HTTP request and the > application logic? -- The concerns and design goals of HTTP servers are different from those of application servers. --- # Server Design Goals ## HTTP Server * Provide a high performance HTTP implementation (handles concurrency) * Be extremely stable, and relatively static * Be very configurable and language/framework agnostic -- ## Application Server * Support a specific language (e.g., Ruby), many of which are not optimized for performance * Run _business logic_ which is extremely dynamic --- # Application Servers We are building web applications, so we will require complex server-side logic. We _can_ extend our HTTP servers to provide this logic through modules, but there are benefits to separating application servers into one ore more distinct processes. Because: -- * Application logic will be dynamic * Application logic regularly uses high level (slow) languages * Security concerns are easier (HTTP server can shield app server from malformed requests) * Setup costs can be amortized if the app server is running continuously --- # Application Server Architectures > What architecture should we use for our application server? -- We have the same trade-offs to consider as with HTTP servers (e.g. threads, processes, and/or workers), so we needn't revisit them again. --- class: center middle # How does an HTTP Server communicate with the application server(s)? --- # Inter-server Communication ## [CGI](https://en.wikipedia.org/wiki/Common_Gateway_Interface) Spawn a process, pass HTTP headers as ENV variables and utilize STDOUT as the response. -- ## [FastCGI](https://en.wikipedia.org/wiki/FastCGI), [SCGI](https://en.wikipedia.org/wiki/Simple_Common_Gateway_Interface) Modifications to CGI to allow for persistent application server processes (amortizes setup time). -- ## HTTP Communicate via the HTTP protocol to a long-running process. (Essentially a reverse-proxy configuration). > Does it make sense to have the application server speak HTTP? --- # Up Next Let's take a quantitative look at various approaches used in actual Ruby application servers. We will not consider evented ruby application servers (e.g., EventMachine) because Rails will not run on such application servers. --- # Our Test Setup  The [Demo App](https://github.com/scalableinternetservices/demo) is a link sharing website with: * Multiple communities * Each community can have many submissions * Each submission can have a tree of comments --- # Simulated Users Using [Tsung](http://tsung.erlang-projects.org/) (erlang-based test framework) we will simulate multiple users visiting the Demo App web service. Each user will: ``` Visit the homepage (/) Wait randomly between 0 and 2 seconds Request community creation form Wait randomly between 0 and 2 seconds Submit new community form Request new link submission form Wait randomly between 0 and 2 seconds Submit new link submission form Wait randomly between 0 and 2 seconds Delete the link Wait randomly between 0 and 2 seconds Delete the community ``` --- # Test Process There are six phases of testing each lasting 60 seconds: 1. (0-59s) Every second a new simulated user arrives 2. (60-119s) Every second 1.5 new simulated users arrive 3. (120-179s) Every second 2 new simulated users arrive 4. (180-239s) Every second 2.5 new simulated users arrive 5. (240-299s) Every second 3 new simulated users arrive 6. (300-359s) Every second 3.5 new simulated users arrive __Note__: Each user corresponds to seven requests and a user may wait up to ten seconds with the delays. --- # Test Environment All tests were conducted on a single Amazon EC2 m3-medium instance. * 1 vCPU * 3.75 GB RAM The tests used the `Puma` application server (unless otherwise specified). The `database_optimizations` branch of the demo app was used to run the tests: [https://github.com/scalableinternetservices/demo/tree/database_optimizations](https://github.com/scalableinternetservices/demo/tree/database_optimizations) --- # Single Thread/Process (Users) .center[] --- # Single Thread/Process (Page Load) .left-column20[ Decrease in performance around 60s (1.5 new users per second) Mean duration's spike is around 200 seconds. ] .right-column80[ .center[] ] --- # Four Processes (Users)  --- # Four Processes (Page Load) .left-column20[ Decrease in performance around 240s (3 new users per second) Mean duration's spike is just below 18 seconds. ] .right-column80[  ] --- # Sixteen Processes (Users)  --- # Sixteen Processes (Page Load) .left-column20[ Decrease in performance around 240s (3 new users per second) Mean duration's spike is just below 14 seconds. Little improvement over 4 processes especially considering up to 4x memory usage. ] .right-column80[  ] --- # Threads instead of processes? > What do you think will happen? --- # Four Threads (Users)  --- # Four Threads (Page Load) .left-column20[ Still decrease in performance around 240s, but more stable until then. Mean duration's spike is about 14 seconds. ] .right-column80[ 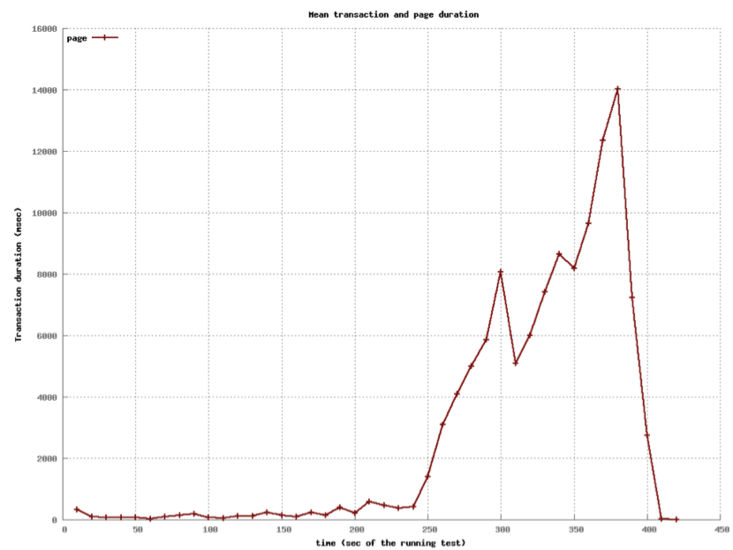 ] --- # 32 Threads (Users) 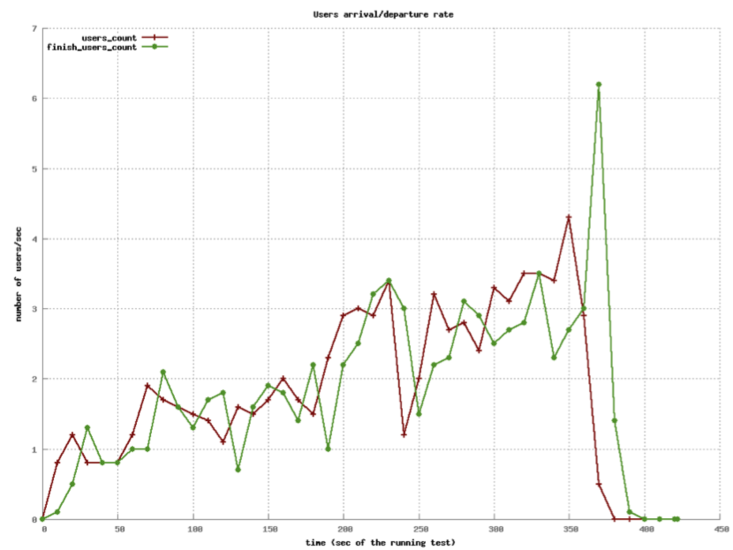 --- # 32 Threads (Page Load) .left-column20[ Decrease in performance beginning around 300s (3.5 new users per second) Mean duration's spike is under 2 seconds. ] .right-column80[ 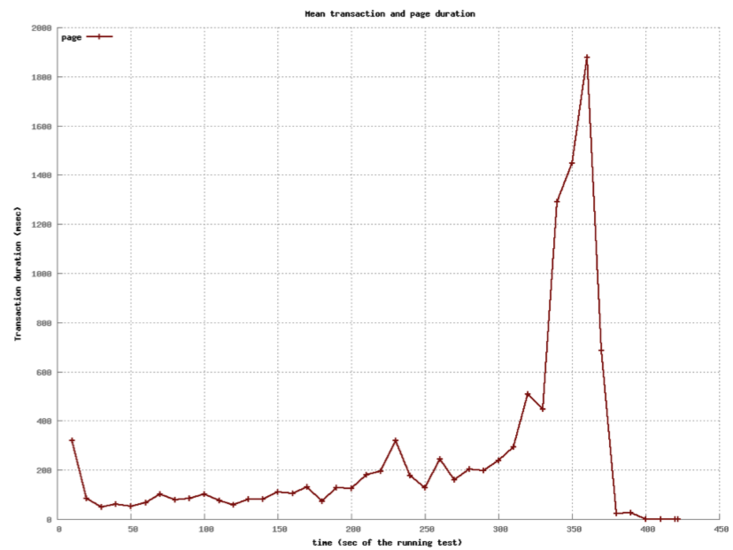 ] --- # Digression: Ruby interpreters There are different versions of the Ruby interpreter. Different workloads may benefit from using different interpreters. ## MRI (Matz's Ruby Interpreter) * The reference version * Written in C * Has a global interpreter lock (GIL) that prevents true thread-concurrency ## JRuby * Written in Java * Does not have GIL --- # Ruby Application Server: Puma - "Puma is a simple, fast, multi-threaded, and highly concurrent HTTP 1.1 server for Ruby/Rack applications." - "Puma ... serves the request using a thread pool. Each request is served in a separate thread, so truly concurrent Ruby implementations (JRuby, Rubinius) will use all available CPU cores." - "On MRI, there is a Global VM Lock (GVL) that ensures only one thread can run Ruby code at a time. But if you're doing a lot of blocking IO (such as HTTP calls to external APIs like Twitter), Puma still improves MRI's throughput by allowing IO waiting to be done in parallel." - "Puma also offers 'clustered mode'. Clustered mode forks workers from a [main] process." - "In clustered mode, Puma can 'preload' your application. This loads all the application code prior to forking." > Why might you want to wait to load the application prior to forking? <https://github.com/puma/puma> --- # Thread Safety Note If you can use thread-parallelism, do it! But, making your code thread safe isn't always obvious. Things to consider: * Your code * Your code's many dependencies