class: center, middle # Scaling Web Applications ## CS291A: Scalable Internet Services --- # Scaling Goal .center[] After today you will understand what load balancing is, and why the depicted architecture provides smooth cost-effective scaling. ??? Our goal today is to understand what the pieces in this architecture are - Load Balancer - Switch - Application Servers - Database Server And why horizontal scaling is a good way to scale web applications --- # The Problem You've built something the world (or significant subset) is excited about. > What do you do when your popularity doubles (again, and again)? --- # The Solutions ## Vertical Scaling Buying "bigger" hardware and scaling _up_ * __PRO__: Easy * __CON__: Limited * __CON__: Non-linear increase in cost when scaling -- ## Horizontal Scaling Buying more servers and scaling _out_ * __PRO__: Easy to add more servers (limited by data center space) * __PRO__: Linear (maybe even sublinear) increase in cost when scaling * __CON__: More moving parts makes things more complicated --- class: center, middle, inverse # Vertical Scaling --- # Vertical Scaling When needed, increase the resources of your current server, eventually buy (or rent) a bigger server with: * More memory * More and/or faster CPUs and/or cores * Higher bandwidth --- # EC2 and Vertical Scaling With Amazon EC2 you rent virtual instances. There are clear vertical scaling paths. Each type of instance (below) has a few options ranging from lower resources/performance to higher resources/performance: * __T__ and __M__ prefixed instances: balanced mix of memory and CPU * __C__ prefixed instances: CPU optimized * __R__ prefixed instances: Memory optimized * __G__ prefixed instances: GPU optimized * __I__ prefixed instances: I/O optimized * __D__ prefixed instances: Storage capacity optimized https://aws.amazon.com/ec2/instance-types/ --- # Test Setup  The Demo App is a link sharing website with: * Multiple communities * Each community can have many submissions * Each submission can have a tree of comments --- # Scaling Test: Simulated Users Using Tsung (erlang-based test framework) we will simulate multiple users visiting the Demo App web service. Each user will: ``` Visit the homepage (/) Wait randomly between 0 and 2 seconds Request community creation form Wait randomly between 0 and 2 seconds Submit new community form Request new link submission form Wait randomly between 0 and 2 seconds Submit new link submission form Wait randomly between 0 and 2 seconds Delete the link Wait randomly between 0 and 2 seconds Delete the community ``` ??? * Compare this to the load test we did in the first lecture. * Rather than just hitting the homepage, we are simulating a user interacting with the site. * This is the type of test we will build up to for your main project * We want to simulate something like a real user interaction * A real user - Will not click through the site as fast as possible - There will be pauses between actions of variable length * Not all users will be doing the same thing at the same time - We need to account for users arriving at different times - We should account for users doing difference sequences of actions --- # Scaling Test: Phases This time we have twelve phases of testing each lasting 60 seconds: ``` 1. (0-59s) Every second a new simulated user arrives 2. (60-119s) Every second 1.5 new simulated users arrive 3. (120-179s) Every second 2 new simulated users arrive 4. (180-239s) Every second 4 new simulated users arrive 5. (240-299s) Every second 6 new simulated users arrive 6. (300-359s) Every second 10 new simulated users arrive 7. (360-419s) Every second 16 new simulated users arrive 8. (420-479s) Every second 20 new simulated users arrive 9. (480-539s) Every second 25 new simulated users arrive 10. (540-599s) Every second 35 new simulated users arrive 11. (600-659s) Every second 45 new simulated users arrive 12. (660-719s) Every second 55 new simulated users arrive ``` ??? * Depending how long a user interaction takes, there may be significant overlap between the users arriving each second --- # Vertical Scaling: M3 Large Instance .left-column20[ * 2 vCPUs * 7.5 GB Memory * SSD storage * $100 per month Handles 6 new users per second (ups). Fails with 10 ups. ] .right-column80[  ] ??? Database and Application server are on the same machine This is our baseline. How can we handle more users? --- # Vertical Scaling: M3 X-Large Instance .left-column20[ * 4 vCPUs * 15 GB Memory * SSD storage * $200 per month Handles 10 new users per second (ups). Fails with 16 ups. ] .right-column80[  ] ??? M3 Large -> M3 X-Large Double the CPU Double the Memory Double the cost Only 1.6x the capacity --- # Vertical Scaling: M3 XX-Large Instance .left-column20[ * 8 vCPUs * 30 GB Memory * SSD storage * $400 per month * Largest available M-prefixed instance. Handles 16 new users per second (ups). Fails with 20 ups. ] .right-column80[  ] ??? M3 X-Large -> M3 XX-Large Double the CPU Double the Memory Double the cost Only 1.25x the capacity Compared to M3 Large 4x the CPU 4x the Memory 4x the cost for ~2.6x the capacity --- # Vertical Scaling: C3 4XLarge Instance .left-column20[ * 16 vCPUs * 30 GB Memory * SSD storage * $600 per month Handles 20 new users per second (ups). Fails with 25 ups. ] .right-column80[  ] ??? M3 XX-Large -> C3 4XLarge Trying a different instance type Double the CPU Same Memory 1.5x the cost 1.25x the capacity Compared to M3 Large 8x the CPU 4x the Memory 6x the cost for ~3.3x the capacity There are largere instance types available... But, there is a limit to vertical scaling What if we could use 6 M3 Large instances for the same cost? Would that let us handle 36 users per second? * In practice, there are some additional overhead costs with horizontal scaling - The load balancer - Separating the application and database servers --- class: center, middle, inverse # Horizontal Scaling --- # Load Balancing Vertical scaling requires fewer moving parts but has limited scaling capability. Eventually horizontal scaling becomes necessary to handle increased load. When horizontally scaling HTTP, this technique is referred to as __load balancing__. ## Basic Idea * Have many servers that can serve clients * Make these servers _appear_ as a single endpoint to the outside world The users' experiences are the same regardless of which server ultimately handles the request. ??? If we have our 6 M3 Large instances, we need a way to distribute the users between them. --- # Think About It > How can we enable many servers to serve clients? -- Consider the following sequence of actions: 1. `GET /products` ( returns a list of products ) 2. `POST /products` ( creates a new product ) 3. `GET /products` ( returns a list of products ) > If these requests are handled by three different servers, will the third > request show the new product? ??? How can we make sure that the third request shows the new product? --- # Stateless Servers .center[] In order for load balancing to work, the servers must be stateless. Statelessness can be accomplished by keeping the persistence layer separate from the application layer. --- # Load Balancing (1): HTTP Redirects .left-column30[ Discussed in section 6.1 of the reading. Implemented using multiple web servers with different domain names. A request for `www.domain.com` will use HTTP 301 or 302 to redirect the request to a pool of possible hosts. ] .right-column70.center[  ] --- # HTTP Redirect Example ```http % nc www.domain.com 80 GET / HTTP/1.1 host: www.domain.com HTTP/1.1 301 Moved Permanently Date: Wed, 15 Oct 2014 21:08:22 GMT Server: Apache/2.2.22 (Ubuntu) Location: http://www2.domain.com/ Content-Type: text/html; charset=iso-8859-1 ... ``` -- > What are the problems with this approach? --- # HTTP Redirects Trade-offs ## Strengths * Simple * Location independent -- ## Weaknesses * Not transparent to user * High load on www * May reduce local-network cache applicability * Users can bypass load balancer ??? * Where would a link served by one of the other servers point to? - Should it point to itself? - Should it point back to the main domain? --- # Load Balancing (2): Round Robin DNS .left-column30[ Discussed in section 4.1 of the reading. When a user's browser queries DNS for `www.example.com`, a list of IPs is returned. The DNS server rotates the list order for each query (or alters priorities). The user's browser chooses which IP to connect to (generally picks the first, or highest priority). ] .right-column70.center[  ] --- # Round Robin DNS Example ``` % host cs291.com cs291.com has address 192.30.252.153 cs291.com has address 192.30.252.154 ``` ``` % host cs291.com cs291.com has address 192.30.252.154 cs291.com has address 192.30.252.153 ``` --- # Round Robin DNS Trade-offs ## Strengths * Simple * Cheap -- ## Weaknesses * Less control over balancing * Modifying the list is inhibited by caching in the browser and proxies ??? * Less control because the DNS server is in charge of the order * DNS isn't refered to often so adapting to changes in load is slow even if the DNS server order is dynamic and load aware * Even if the DNS server is dynamic, the client may cache the response for a long time * DNS gets cached at many levels --- # Load Balancing (3): TCP Load Balancing .left-column30[ Discussed in section 5 of the reading. ## General Idea Rewrite TCP packets to send them to the selected server. This includes addresses, sequence numbers, and checksums. ] .right-column70.center[  ] ## Commercial Products * Citrix Netscaler (hardware ASIC) * F5 Big IP (hardware ASIC) * AWS Network Load Balancer (cloud service) ??? * Multiple ways to do this * Can be done in - hardware - software * Can be done by - rewriting packets - using a proxy --- # TCP Load Balancing HTTP Request ``` (client -> lb) IP D=208.50.157.136 S=216.64.159.149 LEN=60, ID=48397 TCP D=80 S=1421 Syn Seq=899863543 Len=0 Win=32120 (lb -> server) IP D=10.16.100.121 S=208.50.157.136 LEN=60, ID=48397 TCP D=80 S=1421 Syn Seq=899863543 Len=0 Win=32120 (server -> lb) IP D=208.50.157.136 S=10.16.100.121 LEN=48, ID=26291 TCP D=1421 S=80 Syn Ack=899863544 Seq=1908949446 Len=0 (lb -> client) IP D=216.64.159.149 S=208.50.157.136 LEN=48, ID=26291 TCP D=1421 S=80 Syn Ack=899863544 Seq=1908949446 Len=0 (client -> lb) IP D=208.50.157.136 S=216.64.159.149 LEN=154, ID=48401 TCP D=80 S=1421 Ack=1908949447 Seq=899863544 Len=114 HTTP GET /eb/images/ec_home_logo_tag.gif HTTP/1.1 (lb -> server) IP D=10.16.100.121 S=208.50.157.136 LEN=154, ID=48401 TCP D=80 S=1421 Ack=1908949447 Seq=899863544 Len=114 HTTP GET /eb/images/ec_home_logo_tag.gif HTTP/1.1 ``` --- # TCP Load Balancing HTTP Response ``` (server -> lb) IP D=208.50.157.136 S=10.16.100.121 LEN=1500, ID=22237 TCP D=1421 S=80 Ack=899863658 Seq=1908949447 Len=1460 HTTP HTTP/1.1 200 OK (lb -> client) IP D=216.64.159.149 S=208.50.157.136 LEN=1500, ID=22237 TCP D=1421 S=80 Ack=899863658 Seq=1908949447 Len=1460 HTTP HTTP/1.1 200 OK ``` -- Does the TCP load balancer need to set the source IP address to its own? What else could we do? ??? * Leave the source IP address as the client's IP address * Let the server bypass the load balancer and send the response directly to the client * This is called Direct Server Return (DSR) or Direct Routing (DR) * What are the pros and cons of DSR? - Pros: less load on the load balancer - Cons: more complicated to set up - Cons: the server needs to be on the same network as the load balancer - Cons: the server needs to be able to transmit packets with a source IP address that is not its own --- # TCP Load Balancing Trade-offs ## Strengths * More control over which requests go to which servers * Works fine with HTTPS -- ## Weaknesses * Puts practical limits where the servers can be located (same network) * Complicated --- # Load Balancing (4): HTTP Proxy .left-column30[ Also known as "Layer 7 load balancing" Terminate HTTP requests: act like a web server Issue _back-end_ HTTP request to the desired application server. Cloud Services * AWS Application Load Balancer Hardware products: * Citrix Netscaler * F5 Big-IP Many HTTP servers have modules to do this as well (Apache, NGINX) ] .right-column70.center[ 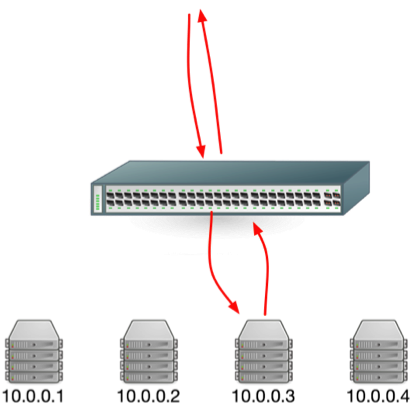 ] ??? * This is the what is commonly called a reverse proxy --- # HTTP Proxy Trade-offs This is the most popular technique in use (#3 is also used). ## Strengths * Easier to implement with off the shelf tools (reverse proxy) * Route traffic based on application layer concerns * HTTP Headers * Request Route * Type of resource being requested (static vs dynamically generated) -- ## Weaknesses * Load balancer needs to do more work * HTTPS is more complicated --- # Load Balancing Considerations Assume you are to design a load balancing HTTP proxy. You have insight into every incoming request and response. > How would you determine which server to forward a request to? -- ## Options * Random * Round robin * Consistent hashing * Least number of connections * Fastest response time * Bandwidth per server * URI-based mapping (e.g., `/images` to server1, `/admin` to server2) Amazon's ELB (elastic load balancer) uses round robin with cookie-based stickiness (send the same client to the same server). --- # Load Balancing Challenges When working with and/or designing a load balancing proxy there are some challenges to consider: * Detecting and reacting to server failures * Session affinity and persistence * Connection pooling Definitions: * __Affinity__: Map a client to a server without application-level information (e.g., IP address, request time) * __Persistence__: Use application-level information to map a client to a server (e.g., cookies) [Reference](https://www.haproxy.com/blog/load-balancing-affinity-persistence-sticky-sessions-what-you-need-to-know/) ??? * Managing the pool of servers - Adding new servers in response to increased load - Removing servers that are not responding - Removing servers when utilzation is low * Making sure that the load balancer is aware of the state of the servers * Persistence is a more reliable mechanism than affinity --- # Detecting Server Failures > How do we know when a member of our application pool has died? Observe traffic. Are requests being processed? Are they just taking a long time? Probe the server through various means: * __ICMP ping__: tests the network and server kernel * __TCP connection__: the process is running and accepting connections * __HTTP HEAD__: the application is serving pages --- # Session Affinity and Persistence > Can we redirect users back to the same web server they used before? > Why would we want to do this? Doing so can provide some caching improvements. A few options: * Affinity based on client IP address (concerns: client IPs change, and IPs are shared) * HTTP Cookie (works but requires proxy configuration) * Session ID in URL (not a great solution) ??? * Caching can make a response faster for a user when affinity and/or persistence is used * Persistence is a more reliable mechanism than affinity --- # Connection Pooling We're used to the idea that one client reuses a TCP connection for many HTTP requests. We can reuse this mechanism for handling many clients over a handful of TCP connections between a load balancer and the application servers. Saves on repeated TCP setup between the load balancer and application servers. Reduces idle waiting on server for reads and writes. ??? * Avoids the overhead of setting up a new TCP connection * Possibly avoids the overhead of setting up a new TLS connection * Reduces the impact of TCP slow start --- # Software Load Balancers * Apache * NGINX * HAProxy * Varnish * Pound * Squid --- # Amazon Elastic Load Balancer Amazon provides load balancing as a service: * $0.025 per load balancer hour * $0.008 per GB of data processed * Works with EC2 autoscaling groups * Supports TLS termination * Supports load balancing between Availability Zones within a Region __Does not__: support load balancing between regions (e.g., between us-west-1 and us-west-2). Consider using Route 53 DNS for region failover. --- # Horizontal Scaling Test In the vertical scaling tests, the database application ran on the same machine as the web server application. For these tests we are going to use a separate EC2 instance for the database. This will make it easy to scale up the number of application server instances. .center[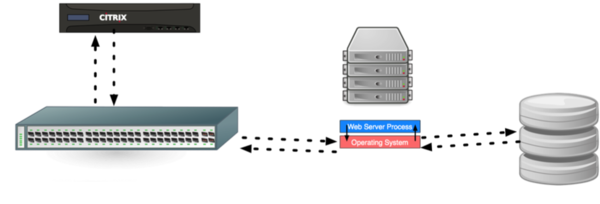] --- # Horizontal Scaling: 1 M3 Large Instance .left-column20[ * 2 vCPUs * 7.5 GB Memory * SSD storage * DB is also M3 large * $200 per month ($100 each) Handles 10 new users per second (ups). Fails with 16 ups. Comparable to single M3 XLarge ($200/mo) ] .right-column80.center[ 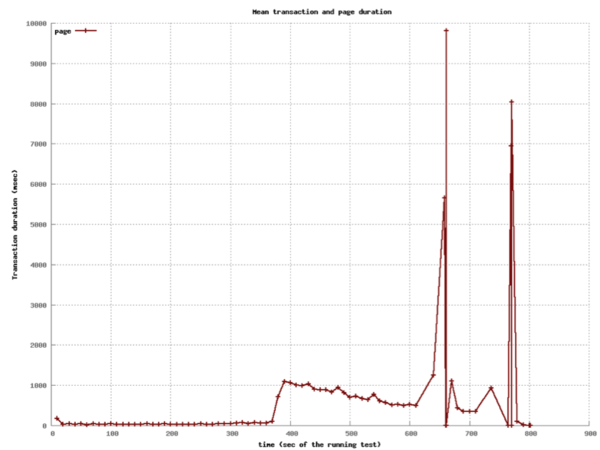 ] ??? * We have extracted the database to its own instance * We can handle 10 new users per second instead of 6 * 2x the cost --- # Adding an App Server Let's scale horizontally by adding a second application server instance. .center[] --- # Horizontal Scaling: 2 M3 Large Instances .left-column20[ * 2 vCPUs * 7.5 GB Memory * SSD storage * DB is also M3 large * $300 per month ($100 each) Handles 20 new users per second (ups). Fails with 25 ups. Comparable to single C3 4XLarge ($600/mo) ] .right-column80.center[ 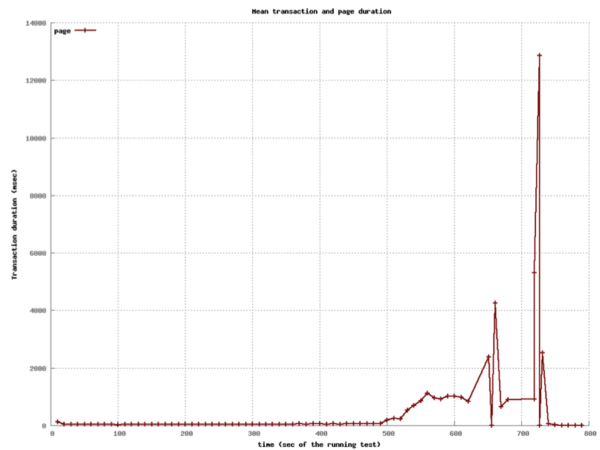 ] --- # More App Servers! .left-column30[ Let’s see how the system performs if we scale out to 5 app servers. Total dollar cost will be comparable to the most expensive single instance we tested. ] .right-column70.center[  ] --- # Horizontal Scaling: 5 M3 Large Instances .left-column20[ * 2 vCPUs * 7.5 GB Memory * SSD storage * DB is also M3 large * $600 per month ($100 each) Handles 35 new users per second (ups). ] .right-column80.center[ 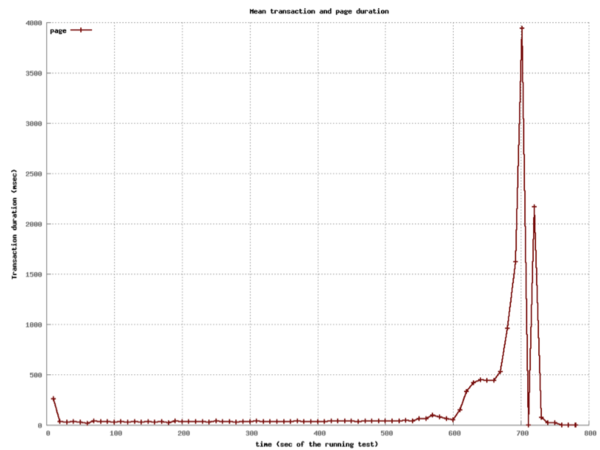 Single C3 4XLarge ($600/mo) failed at 25 ups! ] Handles 45 ups with an increase in response time. Fails with 55 ups. --- # Horizontal Scaling For The Win! Vertical scaling handled only 20 new users per second at a cost of about $600 per month. There was no clear scaling path after that point. Horizontal scaling handled 45 new users per second at a cost of about $600 per month. The scaling path is clear. Add more servers for a linear increase in cost up to some point. --- # So what does load balancing at internet scale look like? 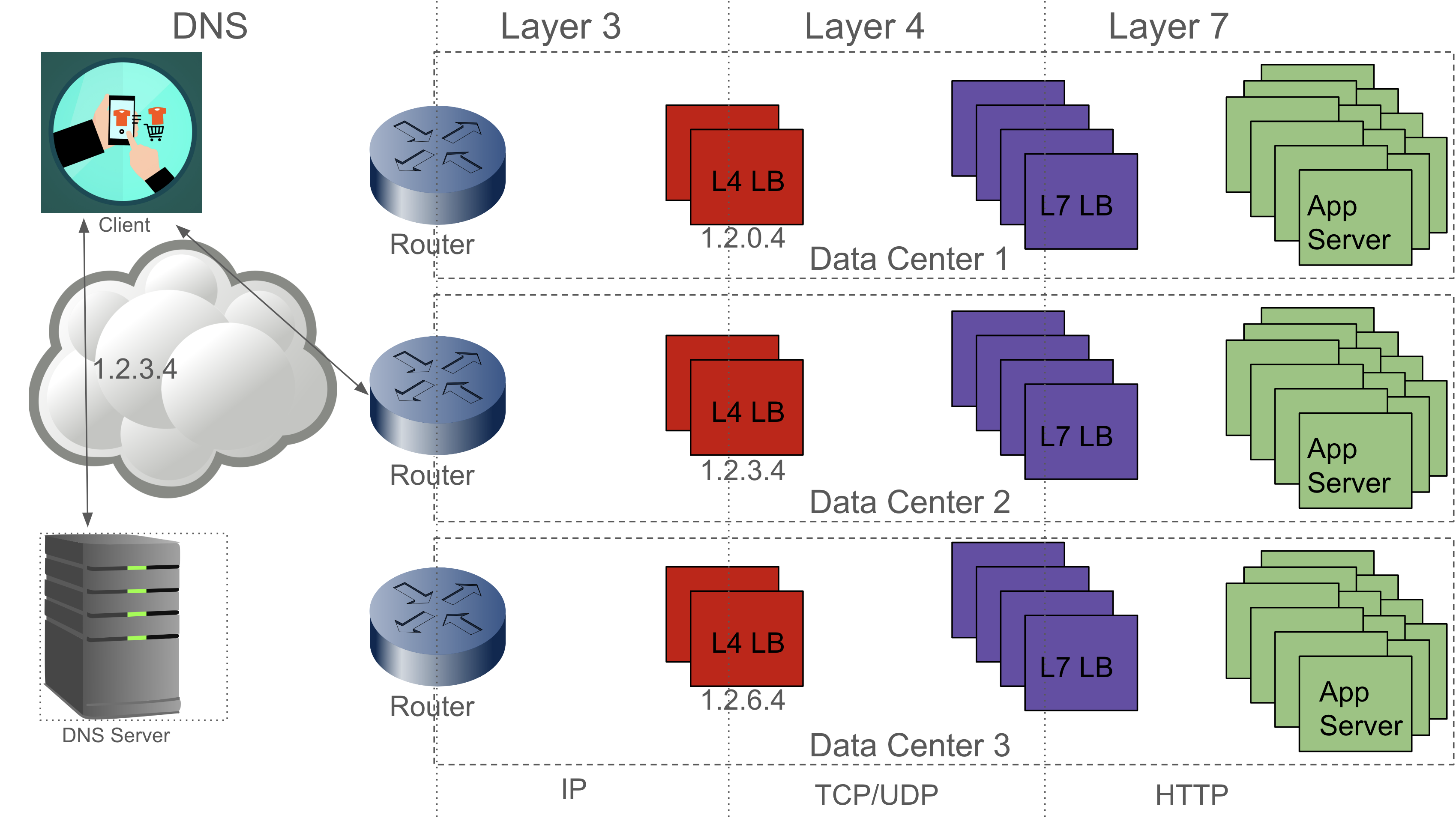 --- # Load Balancing the Load Balancer From Github: http://githubengineering.com/introducing-glb/ From Facebook: https://www.youtube.com/watch?v=dKsOvc73gQk * Slides from Facebook presentation (https://www.slideshare.net/slideshow/buildinga-billionuserloadbalancer-may2015srecon15europeshuff/49665308) ??? * AWS does this for us, but what if we wanted to do it ourselves?